Kubernetes
기본 개념
Container Orchestration
Docker같은 컨테이너들이 여러 개 있을 때, 효율적으로 관리하기위해 필요한 기능들
- Scheduling : 새로운 컨테이너를 띄울 때 가장 적절한 노드를 찾아서 띄워주는 기능
- Scaling : 필요에 따라 적절하게 컨테이너의 수를 늘리고 줄여주는 기능
- Load balancing : 요청이 들어올 때 부하가 어느 한 쪽에 몰리지 않고 여러 컨테이너에 균등하게 분배되도록 도와주는 기능
Cluster
- 여러 컴퓨터를 묶어서 하나의 단위로 다룰 수 있게 만들어주는 개념
- 컨테이너화된 어플리케이션을 어느 누구에게 배포하겠다고 지시할 필요 없이 그냥 클러스터에다가 바로 배포할 수 있게 도와줌
쿠버네티스는 여러 클러스터 사이에서 효율적으로 컨테이너를 분배하고 스케쥴링할 수 있도록 자동화함.
Master + Node
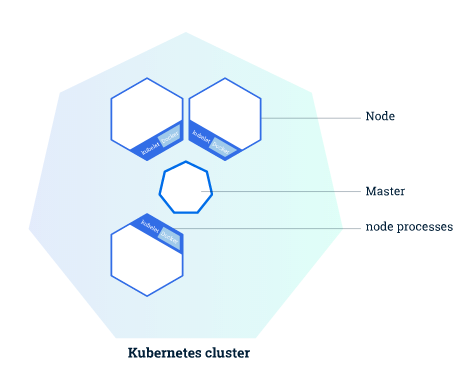
Master
클러스터를 관리하는 역할. 어플리케이션 스케일링, 스케쥴링 등 모든 관리 작업들을 수행
Node
쿠버네티스 클러스터의 워커 머신으로 동작하는 VM 또는 물리 컴퓨터. 각 노드는 클러스터로써 동작하기 위해 마스터와 통신하는 Kubelet이라는 쿠버네티스의 agent를 가짐. 그리고 Docker나 rkt같은 컨테이너 프로그램도 가짐. 하나의 클러스터는 적어도 3개 이상의 노드를 포함하고 있어야 함.
사용자가 새로운 어플을 쿠버네티스에 배포하려고 하면, 먼저 마스터에게 어플 컨테이너를 시작하라고 명령을 내림. 그러면 마스터는 클러스터의 노드에서 새로운 컨테이너를 시작하도록 스케쥴링을 함. 노드는 마스터와 쿠버네이츠 API를 통해서 서로 통신하며, 필요하다면 직접 API를 호출해서 동작하게 만들 수도 있음.
Deployment
Docker에 container가 있다면 쿠버네티스에는 Deployment가 있다고 보면 딱 이해하기 쉬울 듯 함. 마치 docker run 하듯이 kubectl run 을 하고, 각각의 Deployment는 자신의 이름과 바탕이 되는 컨테이너 이미지 주소를 가지게 됨.
일단 쿠버네티스 클러스터 안에서 돌아가고있는 Pods는 기본적으로 외부로 노출되지않고 내부 통신만 가능함. 그러므로 외부로 노출하려면 좀 몇 가지 방법을 써야하는데, 그중 하나는 kubectl proxy 말 그대로 클러스터 안쪽으로 리버스 프록싱을 해줌.
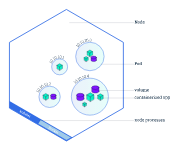
Pods
Pod는 쿠버네티스가 하나 또는 하나 이상의 컨테이너들을 추상화해서 부르는 단위이다. 쿠버네티스 전체 구성에서 제일 작은 atomic한 단위라고 봐도 될듯? 또한 이 컨테이너들이 공유하는 자원도 포함하는데, 그 자원의 목록은 다음과 같다.
- 공유 저장소인 Volume
- 하나의 단일 클러스터 IP 주소
- 컨테이너 이미지 버전이라던가 포트같은 기타 정보들
하나의 Pod은 하나의 논리적 호스트라고 말할 수 있음. 그리고 꼭 한 종류의 컨테이너만 가지는게 아니라 여러가지 컨테이너를 모두 가질 수 있음. 가령 publisher와 subscriber 컨테이너가 모두 한 Pod에 들어갈 수 있다는 이야기. 다만 이 경우 IP 주소와 포트 공간은 서로 공유하게 됨. 그리고 하나의 Pod 안에 들어있는 모든 리소스와 컨테이너들은 같은 위치에 스케쥴링되며, 같은 노드의 shared context 안에서 실행됨.
Pod은 하나의 atomic한 단위임. Deployment를 생성하면 Deployment가 Pod과 그 안의 container들을 생성하게 됨. Pod은 하나의 노드에 할당되며 직접 종료하기 전까지 유지됨. 하지만 노드가 예상치 못한 이유로 망가지게 되면 클러스터 내부의 다른 가용 노드로 옮겨서 다시 시작하게 됨.
Pod은 자신의 lifecycle을 가지고 있고, 언제든지 없어지거나 새로 생성될 수 있음. 그리고 같은 Node에 존재하는 Pod이라고 모두 각자 고유한 IP주소를 가짐. 따라서 서로 다른 Pod 사이에 어떤 관계를 맺을 필요성이 있다면 service discovery가 필요함. 왜냐? 각 Pod은 다른 Pod이 살아있던지 말던지 관계없이 '느슨하게' 동작해야되기 때문.
Service
쿠버네티스의 Service는 pod을 모아놓고 어떻게 접근할 것인지 방법을 정해놓은 하나의 추상화 개념이다. 실질적으로 우리가 쓰게되는 단위라고 봐도 될 듯 하다. YAML, JSON 중 마음에 드는 것으로 작성할 수 있다. 보통은 LabelSelector 을 써서 어느 Pod이 어느 Service인지 가르키도록 한다. Pod이 모두 각자 고유한 IP 주소를 가지고 있기는 하지만 Service 없이는 클러스터 외부로 노출이 되지 않는다. 추상화된 Service를 통해서 접근하기 때문에 그 안에 실제로 작업을 수행하는 pod이 죽어있든 살아있든 또는 복제가 되건 이용자에게는 영향을 주지 않을 수 있다.
Service를 외부로 노출할 때 사용할 수 있는 수단은 다음과 같다.
- ClusterIP : 기본값. Service를 클러스터 내부 IP로 노출시키는 방법이다. 당연하지만 클러스터 외부에서 접근이 불가능하다.
- NodePort : Service를 클러스터에 포함된 Node의 IP와 특정 포트로 노출시키는 방법이다. NAT를 사용하며
NodeIP:NodePort로 접근 가능하다. ClusterIP의 상위호환이다. - LoadBalancer : 클라우드에서 제공하는 로드 밸런서를 쓰는 경우이다. NodePort의 상위 호환이다.
- ExternalName : 말하자면 redirection다. 클러스터 외부에 있는 어떤 다른 서비스를 가르키기 위해서 사용한다. 이 타입을 사용하고 어떤 원하는 외부 호스트를
extenalName값으로 지정해두면 DNS 서비스가CNAME레코드로 그 값을 담아서 되돌려준다. 따라서 DNS 레벨에서 redirection이 발생하고 어떤 proxying이든 forwarding이든 발생하지 않는다.
그리고 Service가 있지만 selector를 사용하지 않는 경우가 두 가지 있는데 하나는 아예 스펙 자체에 selector을 지정하지 않고 사용자가 직접 Service를 특정 엔드포인트에 매핑시키는 경우이고, 나머지 하나는 ExternalName을 사용하는 경우이다.
Label, Selectors
Service가 Pods를 포함하게 되는 기준이라고 볼 수 있을듯. Label은 쿠버네티스 객체에 주어질 수 있는 Key/Value 값임. 여러가지 용도로 사용할 수 있는데 dev, test, real 등 프로필마다 Pods가 나누어지도록 쓸 수도 있고, 그 pod의 버전을 표시할 수도 있음. 그 외에도 갖가지 분류를 위해 사용할 수 있음.
Rolling update
한마디로 정지없이 분산 어플리케이션을 업데이트 하는 것. 당연하지만 한대씩 내리고 업데이트된 버전으로 바꿔서 올리고 그걸 로드밸런서에 붙이면 되는데 쿠버네티스에서는 자동으로 해준다. 그냥 deployment의 image를 변경하면 정해진 만큼 한번에 pod들을 내리고, 그만큼 새로운 이미지로 pod들을 생성해서 서비스에 붙인다. 여기서 쿠버네티스가 갖는 또 다른 장점중 하나는 각 update마다 버저닝을 해두기 때문에 원하는 시점으로 쉽게 rollback할 수 있다는 것이다.
정리하면
하나의 cluster는 여러 개의 node를 가질 수 있고
하나의 node는 여러 개의 pod을 가질 수 있고
하나의 pod은 여러 개의 container을 가질 수 있다
그리고 하나의 deployment는 여러 개의 pod을 생성한다.
service 역시 여러 pod들을 포함할 수 있다.
service와 deployment는 좀 상호 독립적인 관계인데,
service는 pod에 어떻게 접근할 것인지를 정의하고
deployment는 pod을 어떻게 생성하고 관리할 것인지를 정의한다.
리소스는 cluster - node
배포는 deployment - pod - container
아키텍쳐는 front service - middle service - back service - ... 기타 등등 아무튼 서비스와 서비스간의 관계로 구성